I worked on the intricacies of loan-book migration in 2025.
Migrating a loan book involves ensuring that your source’s handling of n types of loans, is clearly matched in terms of data-types as well as action sequence to your destination’s handling of those n types of loans.
Most migrations fail due to the latter half of that sentence: sequence and actions.
To avoid engineering and product bandwidth going into debugging migration (is this mising data or can we not handle this loan type, and hence migration errored out?), I decided to prototype a tool for ideal loan book migration scenarios.
I am still in early thinking and hypothesising stages of this project - but its a useful reminder that nearly all client and project success at enterprise depends on having clean reliable data that’s perfectly structured to destination vagaries.
Logic Layer
The logic layer is not suitable for live-preview, but a screenshot of the tool from my initial analysis is present here.
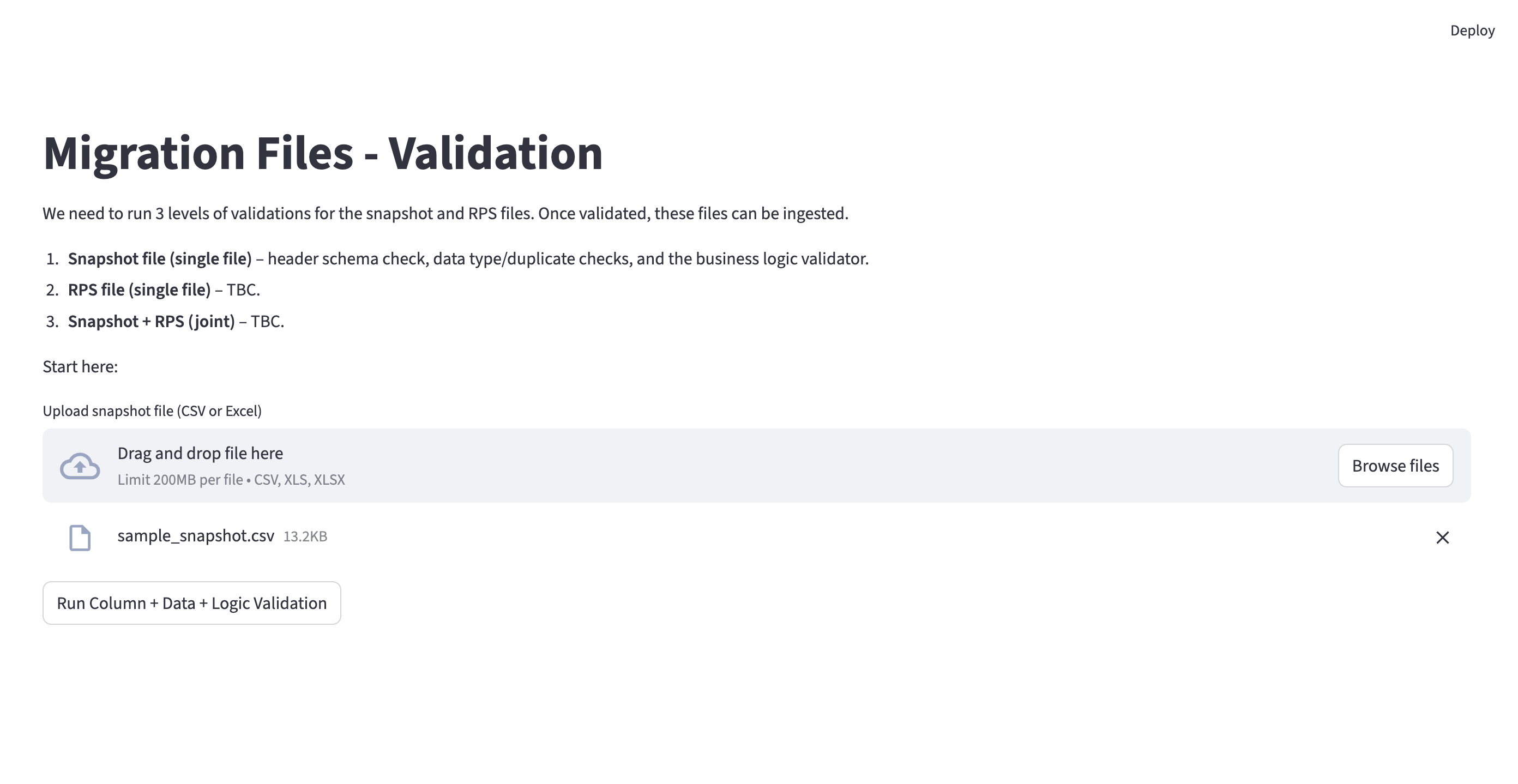
This tool is a multi-phase data validation pipeline designed for loan migration workflows - specifically, verifying snapshot files before they’re ingested.
Each phase produces structured error codes with human-readable descriptions, so operations teams can pinpoint exactly which rows failed and why, without needing to understand the underlying code.
The pipeline is designed to be blocking where it matters (bad headers stop everything) and non-blocking where possible (smaller amount mismatches are flagged but don’t prevent other checks from running).
Logic Layer Demo: how it works
When lenders submit snapshot files containing loan-level data (balances, dates, repayment status, overdue buckets), the validator systematically checks the file across five phases: column schema conformance, duplicate detection, data type and format verification, date chronology logic, and financial reconciliation.
It generates clear, concise error logs, alongside actions that might fix the errors (rename the columns to match ABC template, etc.)
The current implementation is a lightweight Python stack — a Streamlit web UI for file upload, a central validation runner that orchestrates the phases, and individual validator modules for each check.
UI Layer
The example UI is a prototype for structured loan-book ingestion workflow, that can be handled end to end by operations team members alone, without any technical assistance.
The UX breaks migration into explicit stages so ops teams can review data quality before committing records:
- Configure ingestion intent (product + purpose)
- Upload file and map validation scope
- Run staged validation checks
- Review pass/fail summaries with downloadable logs
- Trigger migration and review ingestion outcomes
This prototype focuses on reducing operational misses by turning migration into a guided flow with visible checkpoints, summaries, and next actions.
UI Demo: how it works
In this version, the workflow is deterministic and demo-friendly:
- Status progression is simulated but consistent.
- Validation and migration result views expose clear success/failure states.
- Error and success logs are exportable as CSV for downstream review.
- Navigation mirrors how an operations user would run a migration batch end-to-end.
- This prototype is for operations teams to give feedback on the flow and confidence of the UI/UX.
Production: how this should work
In production, this should become a backend-driven orchestration flow:
- Real file ingestion jobs
- Queue-backed state transitions
- Config-aware rule execution per product and purpose
- Idempotent retries, partial-failure replay, and run resume
- Full audit trail (who triggered, what failed, what was retried)
- LMS write confirmations and reconciliation checks
- Fix suggestions / common error pattern spotting